Finding the Sentiment Hidden in Regulatory Filings
- We used natural-language processing to create a sentiment factor out of company regulatory filings by quantifying how much a company changed its filing and in what sections changes were made.
- A hypothetical equal-weighted portfolio of companies that made the most changes to their regulatory filings (had low exposure to our reporting sentiment factor) strongly underperformed the market.
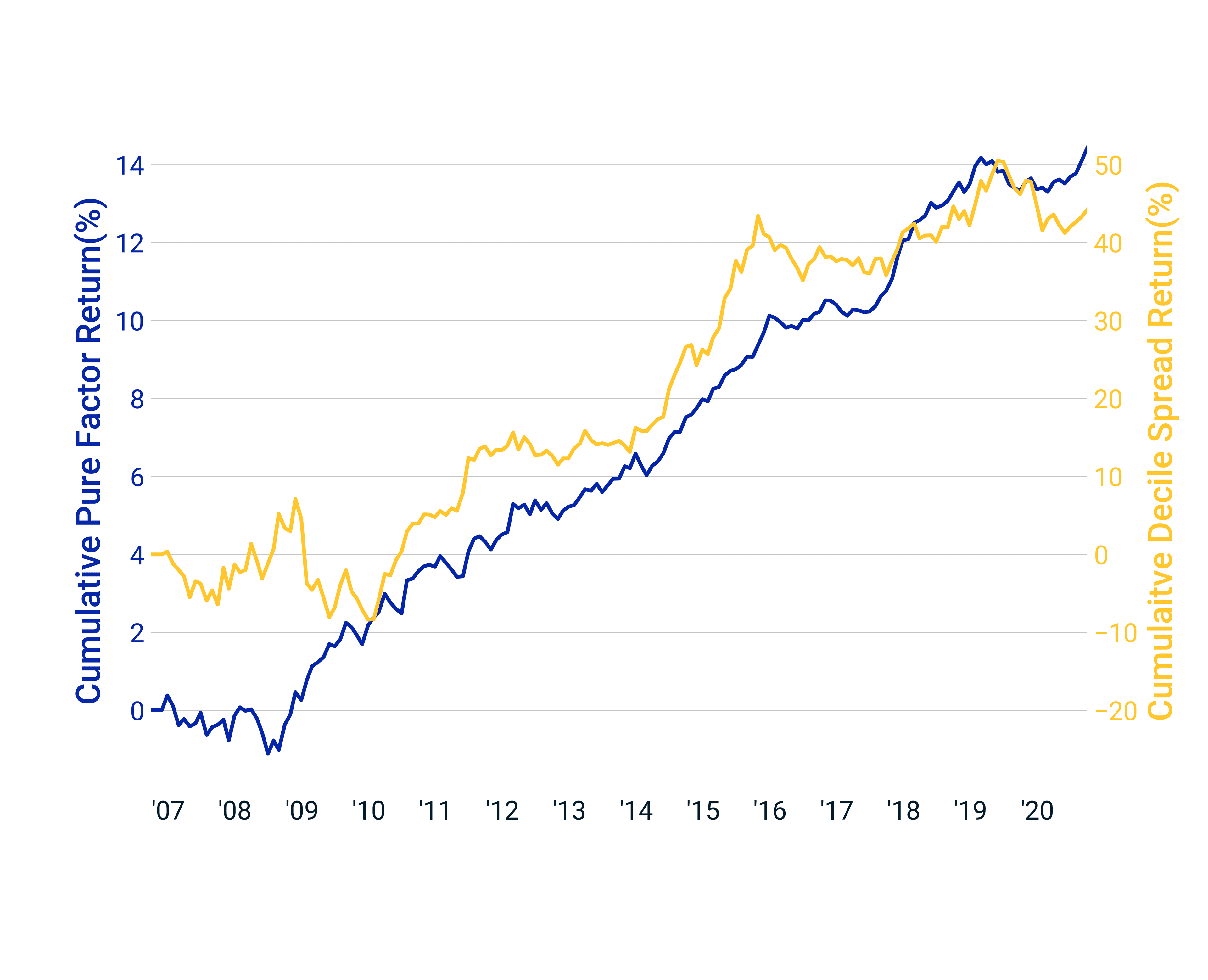
- Our reporting sentiment factor had strong positive performance since 2009 and showed low correlation to traditional style factors throughout the study period.
Descriptor | Definition |
Integrated Document Similarity | Equal-weighted combination of exposure z-scores of the "document similarity" metric computed for: 10-K whole filing, 10-K "Management's Discussion & Analysis," 10-K "Legal Proceedings," 10-Q whole filing (YOY), 10-Q "Management's Discussion & Analysis" (YOY), 10-Q whole filing (QOQ), 10-Q "Management's Discussion & Analysis" (QOQ) |
None | Equal-weighted combination of exposure z-scores of the "document similarity" metric computed for: 10-K whole filing, 10-K "Management's Discussion & Analysis," 10-K "Legal Proceedings," 10-Q whole filing (YOY), 10-Q "Management's Discussion & Analysis" (YOY), 10-Q whole filing (QOQ), 10-Q "Management's Discussion & Analysis" (QOQ) |
Integrated Change in Document Size | Equal-weighted combination of exposure z-scores of the "change in document size" metric computed for: 10-K whole filing, 10-K "Management's Discussion & Analysis," 10-K "Legal Proceedings," 10-Q whole filing (YOY), 10-Q "Management's Discussion & Analysis" (YOY), 10-Q Whole filing (QOQ), 10-Q "Management's Discussion & Analysis" (QOQ) |
None | Equal-weighted combination of exposure z-scores of the "document similarity" metric computed for: 10-K whole filing, 10-K "Management's Discussion & Analysis," 10-K "Legal Proceedings," 10-Q whole filing (YOY), 10-Q "Management's Discussion & Analysis" (YOY), 10-Q whole filing (QOQ), 10-Q "Management's Discussion & Analysis" (QOQ) |
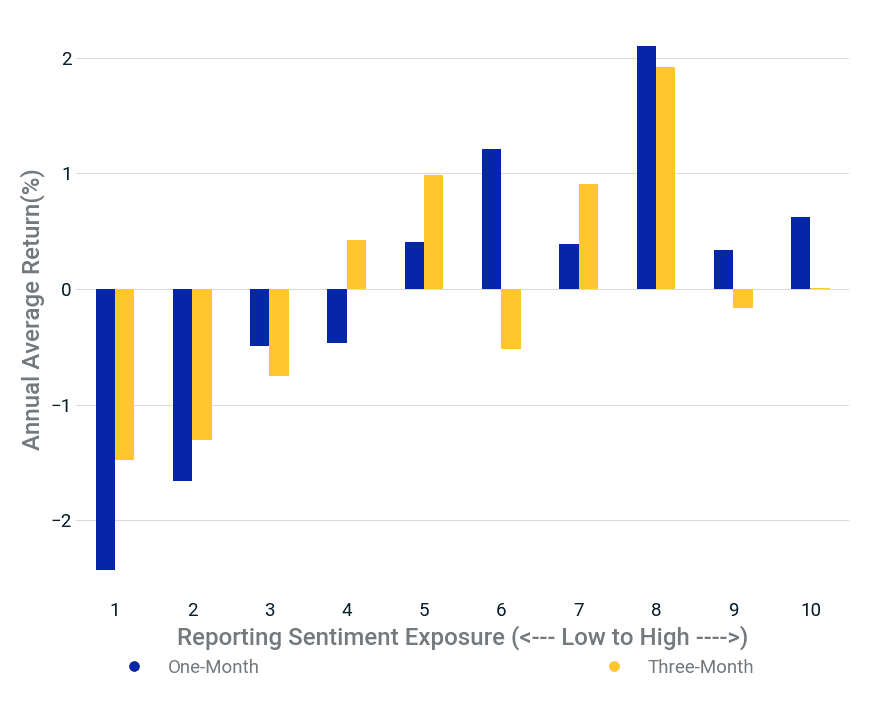
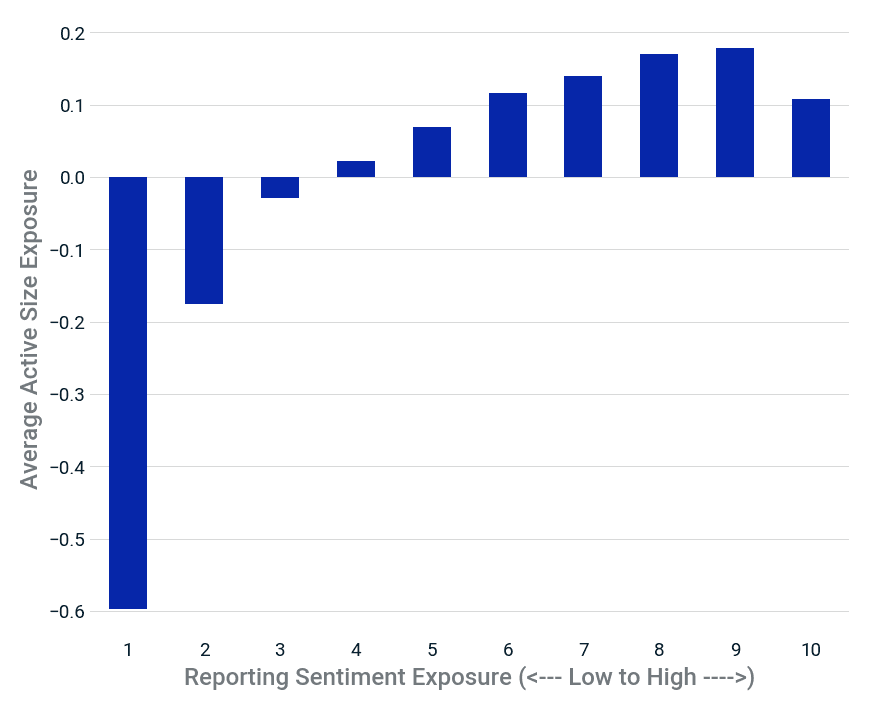
None | Decile portfolio statistics | Decile portfolio statistics | Decile portfolio statistics | Multivariate regression statistics | Multivariate regression statistics | Multivariate regression statistics | Multivariate regression statistics | Multivariate regression statistics | Stability |
None | Decile spread return ,% | Decile Spread volatility ,% | Decile spread IR | Factor return ,% | Factor volatility ,% | Factor IR | Mean |t| | |t| > 2, % | Exposure auto correct |
Reporting Sentiment | 3.06 | 6.4 | 0.48 | 1.03 | 0.87 | 1.18 | 1.06 | 11.38 | 0.82 |
Reporting Sentiment | None | None | None | None | None | None | None | None | None |
3.06 | None | None | None | None | None | None | None | None | None |
6.4 | None | None | None | None | None | None | None | None | None |
0.48 | None | None | None | None | None | None | None | None | None |
1.03 | None | None | None | None | None | None | None | None | None |
0.87 | None | None | None | None | None | None | None | None | None |
1.18 | None | None | None | None | None | None | None | None | None |
1.06 | None | None | None | None | None | None | None | None | None |
11.38 | None | None | None | None | None | None | None | None | None |
0.82 | None | None | None | None | None | None | None | None | None |
Integrated Document Similarity | 0.73 | 7.45 | 0.1 | 0.65 | 0.88 | 0.74 | 1.05 | 11.38 | 0.93 |
Integrated Document Similarity | None | None | None | None | None | None | None | None | None |
0.73 | None | None | None | None | None | None | None | None | None |
7.45 | None | None | None | None | None | None | None | None | None |
0.1 | None | None | None | None | None | None | None | None | None |
0.65 | None | None | None | None | None | None | None | None | None |
0.88 | None | None | None | None | None | None | None | None | None |
0.74 | None | None | None | None | None | None | None | None | None |
1.05 | None | None | None | None | None | None | None | None | None |
11.38 | None | None | None | None | None | None | None | None | None |
0.93 | None | None | None | None | None | None | None | None | None |
Integrated Change in Document Size | 2.37 | 5.21 | 0.45 | 0.76 | 0.73 | 1.04 | 0.98 | 8.39 | 0.7 |
Integrated Change in Document Size | None | None | None | None | None | None | None | None | None |
2.37 | None | None | None | None | None | None | None | None | None |
5.21 | None | None | None | None | None | None | None | None | None |
0.45 | None | None | None | None | None | None | None | None | None |
0.76 | None | None | None | None | None | None | None | None | None |
0.73 | None | None | None | None | None | None | None | None | None |
1.04 | None | None | None | None | None | None | None | None | None |
0.98 | None | None | None | None | None | None | None | None | None |
8.39 | None | None | None | None | None | None | None | None | None |
Reporting Sentiment |
3.06 |
6.4 |
0.48 |
1.03 |
0.87 |
1.18 |
1.06 |
11.38 |
0.82 |
Integrated Document Similarity |
0.73 |
7.45 |
0.1 |
0.65 |
0.88 |
0.74 |
1.05 |
11.38 |
0.93 |
Integrated Change in Document Size |
2.37 |
5.21 |
0.45 |
0.76 |
0.73 |
1.04 |
0.98 |
8.39 |
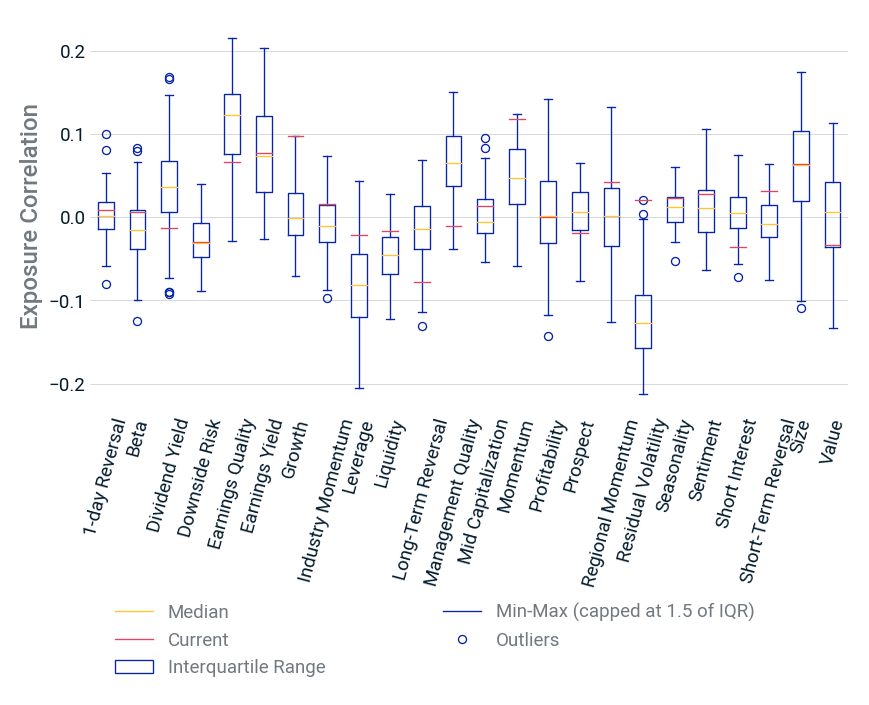
Brown, Steven and Wu Tucker, Jennifer. 2011. "Large‐Sample Evidence on Firms' Year‐over‐Year MD&A Modifications." Journal of Accounting Research. 49 (2): 309-346; Cohen, L., Malloy, C., and Nguyen, K. 2020. "Lazy Prices." The Journal of Finance


Subscribe todayto have insights delivered to your inbox.
The content of this page is for informational purposes only and is intended for institutional professionals with the analytical resources and tools necessary to interpret any performance information. Nothing herein is intended to recommend any product, tool or service. For all references to laws, rules or regulations, please note that the information is provided “as is” and does not constitute legal advice or any binding interpretation. Any approach to comply with regulatory or policy initiatives should be discussed with your own legal counsel and/or the relevant competent authority, as needed.